Hace algún tiempo me tope por casualidad con un reto que proponen en la sección de reclutamiento en una conocida empresa que se dedica a la visualización de datos sobre mapas (no quiero poner el nombre directamente, que el reto sigue activo en su web y no quiero fastidiarles si alguien «Googlea» para ver como hacerlo). El reto consiste en obtener un fichero .csv de aproximadamente 2GB de Internet y hacer algunos cálculos sobre los datos que contiene, lo más rápidamente posible. Esta claro que el ejercicio es para ver como los nuevos aspirantes plantean una posible solución, ya que el resultado, entre otras cosas, dependerá mucho de la velocidad de la red en la que se ejecute el programa. Recordemos, el requisito es ir lo más rápido posible y hay que descargar un fichero de 2GB.
El stack tecnológico de esta empresa es Python, pero como a mí lo que me gusta es C#, acepté el reto, pero en mi lenguaje.

Al final conseguí unos tiempos de ~30 segundos en una red de 600 megas (que según comente con los creadores del reto en Twitter, no esta nada mal) con un programa de consola en .Net Core, vamos a ver como lo enfoqué.
Lo primero que me vino a la cabeza con el reto era como hacer para bajar un fichero de 2GB de Internet y procesar los datos que contiene. El tamaño de bajada te lo has de «comer», pero ¿y si podemos ir bajando el fichero a trozos? Además, no tengo la necesidad de guardar ese fichero, solo necesito el total de filas y un sumatorio de todos los valores de una columna en concreto, por lo que ¿y si ademas de bajar por trozos, lanzamos varios hilos en paralelo para que cada uno baje un trozo distinto? Finalmente, vamos haciendo los cálculos a medida que descargamos cada uno de las partes del fichero. Así, que resumiendo, plantee el reto de la siguiente manera:
- Bajar el fichero por partes.
- Bajar varias partes en paralelo.
- Guardar los valores que necesito para los cálculos a medida que bajo.
Ahora voy a entrar en cada una de las partes, pero el resultado sería algo así:
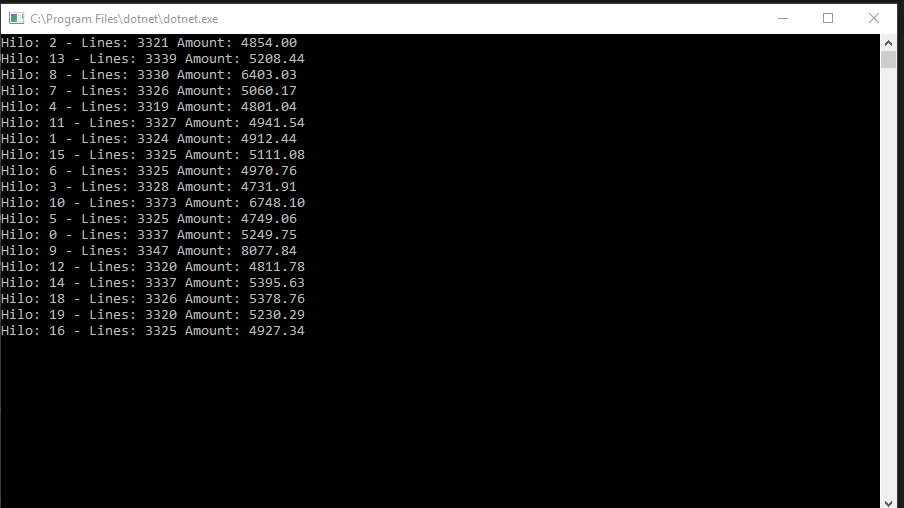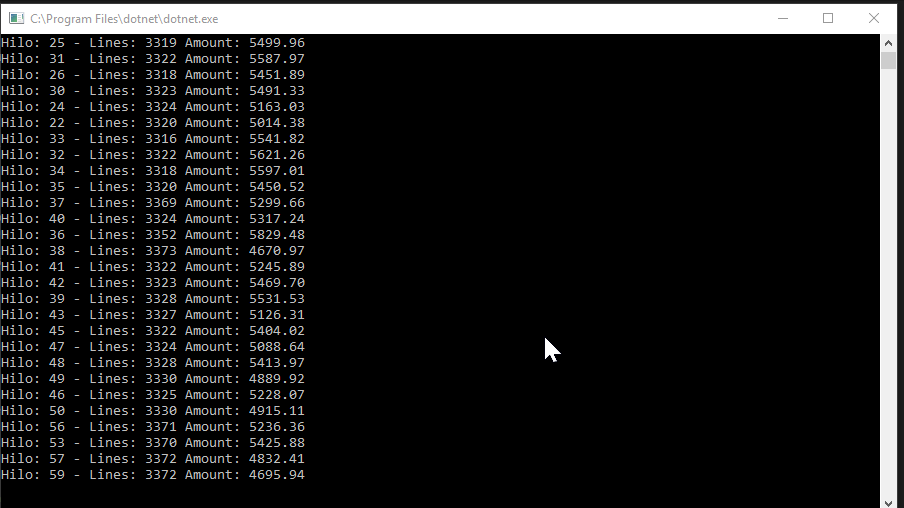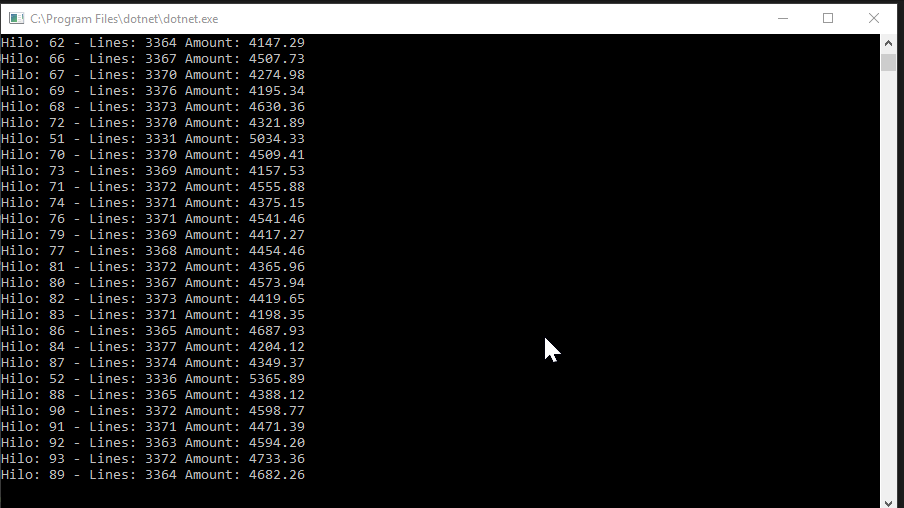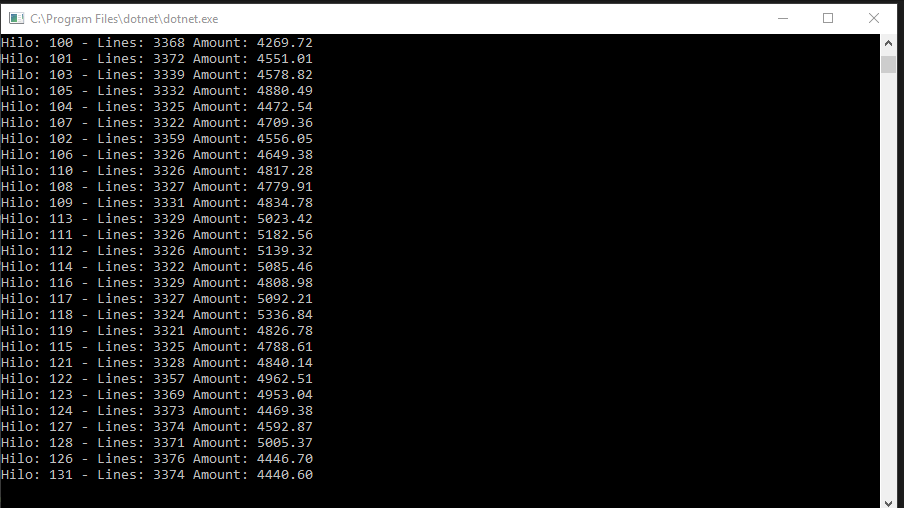
Bajar el fichero por partes
Para poder hacer esto lo primero es que el servidor permita requests parciales. En este caso lo soporta y podemos añadir la cabecera content-range a la petición:
var client = new HttpClient();
client.DefaultRequestHeaders.Range = new System.Net.Http.Headers.RangeHeaderValue { };
client.DefaultRequestHeaders.Range.Ranges.Add(new System.Net.Http.Headers.RangeItemHeaderValue(start, start + blockSize + maxLinSize));Bajar en paralelo
Una vez que tenemos claro el tema de bajar solo una parte del fichero, para ir más rápidos tenemos que paralelizar la cosa. Para eso he utilizado ParallelForEachAsync. Esto permite lanzar varias iteraciones en paralelo y sin bloquear el hilo.
Vamos a ver el código:
Enumerable.Range(0, totalLength / (int)blockSize).ParallelForEachAsync(
async (x) =>
{
var start = x * blockSize;
lista.Add(await Hilo(start, x));
}, 16).Wait();Aquí calculo en cuantos trozos voy a tener que trocear el fichero para leerlo entero y lanzo la operación de leerlo (Hilo. Podéis revisar el código subido al github, pero básicamente lo que hace es leer el fichero y coger los valores que necesitamos) en paralelo. Le indico 16 hilos como máximo (mas no mejoraba nada), guardo el resultado en una lista (que en el siguiente punto veremos) y finalmente espero a que termine antes de continuar. Luego ya solo tendré que usar los valores de la lista para realizar las operaciones finales.
Guardar los valores
Una vez estamos procesando el fichero en varios hilos, tenemos que guardar los valores que estamos procesando. El reto nos dice que necesitamos obtener:
- Número de lineas totales
- El valor medio de la columna «tip_amount»
Para tener el total, tenemos que hacer que cada hilo guarde el número de lineas que ha procesado y el valor medio de la columna, en su «trocito» de fichero. Mas adelante usaremos todos esos valores para hacer el cálculo final una vez procesado todo el fichero.
Para ello he creado una lista del tipo tupla y ademas he hecho que sea concurrente:
System.Collections.Concurrent.ConcurrentBag<Tuple<long, decimal>> lista = new System.Collections.Concurrent.ConcurrentBag<Tuple<long, decimal>>();
ConcurrentBag nos permite tener una lista thread-safe, por lo que podemos ir añadiendo elementos en ella desde distintos hilos sin miedo: