Siguiendo con el tema de los microservicios que inicie en mi primera entrada del blog, voy a hablar del almacenamiento de los datos cuando trabajamos usando este tipo de arquitectura. No tendría mucho sentido que diseñásemos una arquitectura orientada a que sea muy escalable y muy independiente entre sus distintos módulos, para que luego la capa de almacenamiento de los datos nos limite precisamente en estos aspectos. Por eso, cuando trabajamos con microservicios una buena estrategia es crear una base de datos por servicio (al fin y al cabo, un microservicio es un proyecto entero en si mismo) en vez de una única compartida. De lo contrario, estaríamos creando cuello de botella y acoplamiento entre los servicios, que es precisamente lo que queremos evitar.
Las bases de datos relacionales tipo SQL o MySql no son las mejores opciones para algo así, por lo que suele ser mucho mejor optar por una base de datos del tipo NoSQL como puede ser MongoDB (del cual hablare en futuras entradas), o si tienes la posibilidad de trabajar con Azure, puedes usar Tables, que son ideales para almacenar grandes cantidades de datos no estructurados y no relacionados.
¿Por que tables? Si las características del microservicio te lo permiten, es menos costoso (económicamente hablando) y pueden llegar a ser muy rápidas.
Microsoft Azure Storage ofrece cuatro servicios de almacenamiento en la nube: objetos Blobs, Tablas NoSql, colas de mensajes y recursos compartidos:
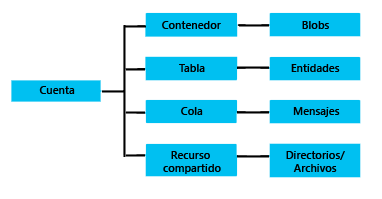
Y aunque en el futuro quiero hablar de todos (o casi) ellos, en esta entrada vamos a a trabajar con Azure Tables.
Recursos necesarios
Para la realización de este post he utilizado las siguientes herramientas (todas gratuitas):
- Visual Studio 2015. Desde aquí, puedes bajar la última versión gratuita.
- Azure Storage Emulator, se incluye dentro de Azure SDK, que puedes descargar desde aquí.
- SQL Server Express (para emular el storage)
Azure Storage Emulator
Para la realización de las pruebas que voy a hacer para el post voy a usar Azure Storage Emulator, que viene incluido en el pack de Azure SDK. El emulador de almacenamiento nos proporciona un entorno local con el que poder desarrollar y hacer pruebas de nuestro código, no olvidemos que estamos hablando de servicios en la nube. Usando el emulador no necesitamos crear una cuenta de Azure o en al caso de que ya tengamos una, nos permite desarrollar sin incurrir gastos en la cuenta.
Una vez descargado e instalado el SDK de Azure podemos abrir la consola para comenzar con la configuración.
Se abre la consola de Azure Storage Emulator:
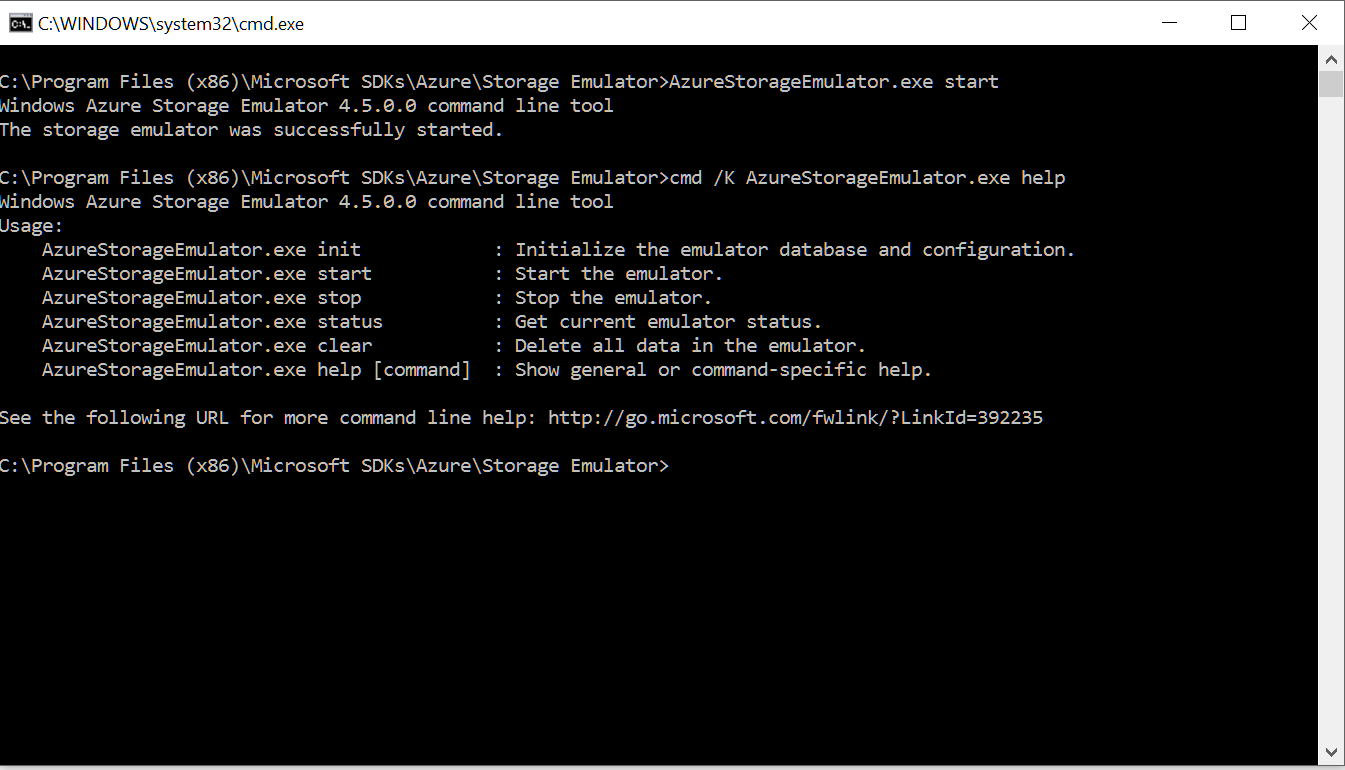
Una vez abierta la consola, automáticamente se listan los distintos comandos de acción para el emulador: init, start, stop, status y clear.
Lo primero que hay que hacer es inicializar el emulador.Yo lo he inicializado indicándole el servidor (en este caso mi maquina) y la instancia de SQL que quiero que utilice para almacenar los datos localmente:
AzureStorageEmulator.exe init -server PORTATIL852-PC -sqlinstance SQLEXPRESS -forcecreate
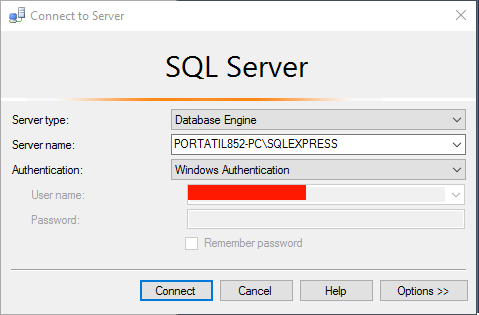
Ahora ya tenemos el emulador funcionando, puedes comprobar el estado con el comando status:
AzureStorageEmulator.exe status

Una vez inicializado ya podemos pararlo o arrancarlo según nos convenga con stop y start:
AzureStorageEmulator.exe start
AzureStorageEmulator.exe stop
Ya tenemos el emulador listo para trabajar, ahora los datos se almacenaran en una tabla en nuestro SQL local que emulará el almacenamiento de Azure Tables.
Mas información del emulador aquí.
Azure Tables
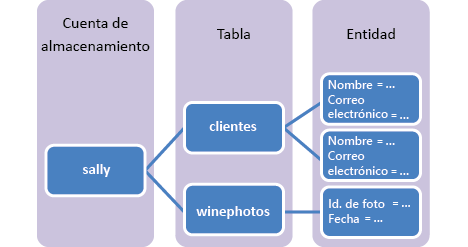
Antes de ponernos manos a la obra con el código, es importante conocer, aunque sea solo un poco, como funciona Azure Tables.
Hay que tener varias consideraciones a la hora de ponernos a diseñar la tabla, es un tema que da para un artículo entero (de los largos) dedicado solo a eso, así que de momento solo hablare de la PartitionKey y la RowKey.
Hemos de tener en cuenta que Azure Tables es un almacén de datos NoSQL del tipo Clave-Valor que para generar la clave primaria usa la propiedad PartitionKey y la RowKey combinadas. Usando la PartitionKey, Azure nos va a proporcionar un escalado automático de nuestra tabla. Para explicar esto mejor, imaginaos una tabla donde almacenáis usuarios, dependiendo de la lógica de negocio, una estrategia de clave primaria podría ser usar la ciudad como clave de partición y el DNI como clave de Row.
Algo parecido a esto:
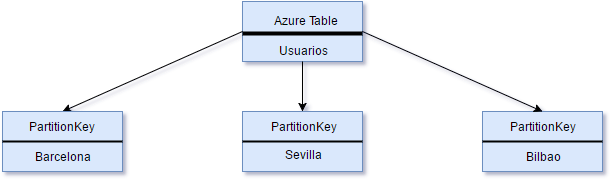
La propiedad RowKey sería el equivalente al ID. En nuestro ejemplo tendríamos a los usuarios particionados por ciudad y con el DNI como ID.
Ahora que ya tenemos la tabla preparada en nuestro entorno local y conocemos por encima como trabaja Azure Tables, por lo que ya solo nos queda ver como «trastear» con datos, para ello vamos a ver algo de código (¡por fin!). En la web de Microsoft tienen ejempos muy completos para trabajar con Tables, por lo que no voy a copiar todo aquí.
Ejemplos de código para trabajar con Tables.
Una vez te hayas empapado de los ejemplos para trabajar con Tables, estaría bien crear un repositorio genérico para Azure Tables que puedas usar en tus proyectos. Aquí os dejo un ejemplo:
En próximas entradas explicaré como crear el servicio en Azure y algunas herramientas útiles para trabajar con Tables.
Referencias
https://docs.microsoft.com/es-es/azure/storage/storage-use-emulator
https://docs.microsoft.com/en-us/azure/storage/storage-table-design-guide
Deja una respuesta