Hoy quiero hablarte de algo realmente interesante y crucial en el desarrollo de IA generativa: los Modelos de Lenguaje Grande, o LLMs (por sus siglas en inglés). Si alguna vez te has preguntado cómo funcionan herramientas como ChatGPT o te gustaría saber cómo podrías utilizar estos modelos en tus propios proyectos, ¡este artículo es para ti!
¿Qué es un LLM y por qué son tan Importantes en la IA Generativa?
Antes de explorar cómo podemos usar los LLMs, empecemos por entender qué son. Un LLM o Modelo de Lenguaje Grande es un modelo de inteligencia artificial entrenado con cantidades masivas de datos de texto. Estos modelos tienen la capacidad de generar y comprender lenguaje natural de una forma increíblemente avanzada, imitando cómo escribimos y hablamos los humanos. Por ejemplo, herramientas como ChatGPT pueden crear textos coherentes a partir de una simple instrucción, lo que los hace muy útiles en múltiples aplicaciones.
¿Por qué son tan relevantes en la IA generativa? Porque permiten que las máquinas generen contenido por sí mismas: escribir correos, programar, crear imágenes, ¡las posibilidades son infinitas! Los LLMs están revolucionando sectores como la atención al cliente, el marketing y la producción creativa, y su capacidad de aprender patrones de lenguaje les permite responder con coherencia y creatividad. En resumen, han llegado para cambiar la manera en que interactuamos con la tecnología.
Usando LLMs como Servicio: Fácil y Práctico
Hoy en día, integrar LLMs en proyectos es más sencillo que nunca gracias a servicios como los de OpenAI, Microsoft con Azure y Hugging Face, que ofrecen APIs para usar LLMs sin necesidad de entrenarlos ni alojarlos por nuestra cuenta. Estos servicios eliminan la preocupación por la infraestructura y el mantenimiento, y ofrecen una gran escalabilidad. Si tienes una aplicación pequeña que crece rápidamente, estas plataformas pueden gestionarlo sin problemas.
Eso sí, vale la pena tener en cuenta los costes: por ejemplo, usar GPT-4 en la nube puede costar algunos céntimos por cada 1.000 tokens, y a largo plazo podría resultar caro. Si prefieres alojar el modelo en tu propio servidor para reducir costos, prepárate: necesitarás una infraestructura considerable para hacerlo.
¿Qué Necesitas para Alojar tu Propio LLM?
Si quieres dar un paso más y alojar tu propio LLM, ¡aquí es donde se pone interesante! Para ejecutar un modelo grande como GPT, necesitas GPUs de alta potencia, como las NVIDIA H100, cuyo precio ronda los 25.000 euros y consume hasta 700W de energía. Para un modelo de la escala de GPT-4, necesitarías al menos 11 de estas GPUs, junto con servidores capaces de soportarlas.

Existen alternativas más pequeñas, como los modelos OpenLLaMA, que pueden ejecutarse en GPUs de gama alta más accesibles. Un modelo con 8B de parámetros podría funcionar en una GPU con 16GB de VRAM, aunque depende de cuánto se cuantifique el modelo, algo que exploraremos en el siguiente apartado.
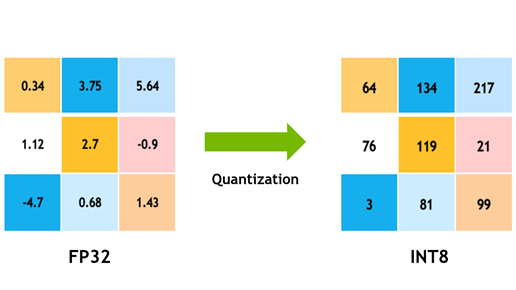
Cuantización: Hacer los Modelos más Ligeros
La cuantización es una técnica para reducir el tamaño de los LLMs sin perder demasiado en precisión o rendimiento. Se trata de representar los pesos (las conexiones entre las neuronas del modelo) con números más pequeños, lo que ahorra memoria y acelera el cálculo.
Cuanto más cuantices el modelo, más precisión perderás. Sin embargo, dependiendo de tus necesidades, puedes encontrar un equilibrio adecuado entre eficiencia y rendimiento, permitiendo que el modelo funcione en hardware con menos capacidad sin sacrificar demasiado en calidad.
Costo de Ejecutar vs. Entrenar un LLM
Ejecutar un LLM en tu propio hardware ya es costoso, pero entrenarlo desde cero es otra historia. Modelos como GPT-3 (con 175B parámetros) requieren miles de GPUs y millones de horas de cómputo para ser entrenados. Es por eso que muchas empresas prefieren usar modelos preentrenados y personalizarlos para sus necesidades en lugar de entrenarlos desde cero, algo que exploraremos más a fondo en esta serie de artículos.
Seguridad en el Uso de LLMs como Servicio
Cuando interactúas con un LLM en la nube, estás enviando datos a un proveedor externo, lo que implica ciertos riesgos de seguridad. Es crucial tomar medidas, como cifrar los datos y anonimizar información sensible. Además, técnicas como RAG (Retrieval-Augmented Generation) pueden mejorar la seguridad. RAG permite que el modelo acceda a bases de datos externas controladas en tiempo real para generar respuestas precisas sin almacenar información sensible.
Conclusión: ¿Te Atreves a Probar un LLM?
Usar un LLM como servicio es una manera sencilla y práctica de integrar IA generativa en tus proyectos. Sin embargo, si quieres dar el paso extra de ejecutar tu propio modelo, prepárate para los desafíos. En el próximo artículo, exploraremos cómo usar LLMs con APIs y algunos frameworks como LangChain o Semantic Kernel que facilitan esta tarea. ¡No te lo pierdas y cuéntame en los comentarios qué modelo de IA te gustaría probar!
Deja una respuesta