Hola, el otro día estaba leyendo el libro de Satya Nadella (Pulsa refrescar, lo recomiendo mucho, esta regalado en Amazon) en el que habla de cómo ha liderado el cambio tanto tecnológico como cultural en Microsoft. Una de las cosas que dice es que a él lo que le funciona es la empatía, el ponerse en el lugar de los otros. Así que he reflexionado un poco sobre el tema y he pensado que tal vez, desde la parte tecnológica, a veces no se explica lo suficiente el porqué de ciertas decisiones que tomamos y, por lo tanto, no se están entendiendo desde áreas no técnicas. A veces es por nuestro ego (hablo por mí, por supuesto), el orgullo, la falta de empatía o el hecho de que tal vez no se nos escucha como se debería desde las áreas no tecnológicas. Tal vez la suma de todo.
He pensado que tal vez, explicando algunos casos de decisiones que he tomado con más detalle, sin hablar en idioma puramente técnico. Por lo tanto, voy a iniciar una serie de entradas en el blog en las que hablare de algunas decisiones que he tomado y el por que de estas. Tal vez tenga suerte y consiga un debate interesante.
Contexto
El contexto es importante, los datos se convierten en información gracias al contexto. El contexto del proyecto en el que tome esta decisión es que teníamos un D365 Field Service que, entre otras cosas, tenia “que hablar y entenderse” con otros sistemas del cliente, en este caso un SAP. La volumetría no es exagerada, pero tampoco es pequeña y tendremos puntualmente unas cargas de datos brutales. Las entidades que tenemos que cargar en D365 son complejas, y tienen muchas relaciones en nuestro modelo de Dataverse (aka CDS), con muchas validaciones. Además, las especificaciones cambian continuamente. Esto no lo sabíamos al principio, pero vamos, nuestra experiencia ya nos puede hacer intuir, que cuanto menos definido este el funcional al principio, mas propensión al cambio va a tener. Es más, incluso con funcionales súper definidos, el cambio durante el proyecto es inevitable. ¿Cómo se puede afrontar algo así? No existen balas de plata en esto del desarrollo e implantación de proyectos, por lo que se puede afrontar de distintas formas.
Solución
Podríamos haber pensado en una ETL con Azure Data Factory tal vez, pero las integraciones tenían que ser en tiempo real, bajo demanda del sistema SAP, por lo que hay que descartar esta opción, que por ejemplo podría haber sido una buena opción si las cargas fuesen nocturnas.
Podríamos entonces haber montado un punto de entrada con un Power Automate, esto del low code podría ser un acelerador del desarrollo. Tal vez si fuesen integraciones puntuales o con entidades menos complejas. Pero con estos volúmenes, transformaciones y validaciones, hubiese sido más complicado hacerlo funcionar correctamente con low code que usar otro sistema, además del mantenimiento y la gestión del cambio se hubiese complicado.
Al final, opte por crear y programar una API REST en .NET, alojada en un Azure Web App que se encargaría de recibir las peticiones de integración, realizar las validaciones y transformaciones necesarias para finalmente insertar los datos en Dataverse. ¿Qué nos ha permitido crear esta capa intermedia? Os comento:
– Control: Un único punto de entrada al CDS desde los distintos sistemas del cliente. Además, un punto de entrada controlado por nosotros. Controlamos que entidades están afectadas y que datos entran y salen del CDS.
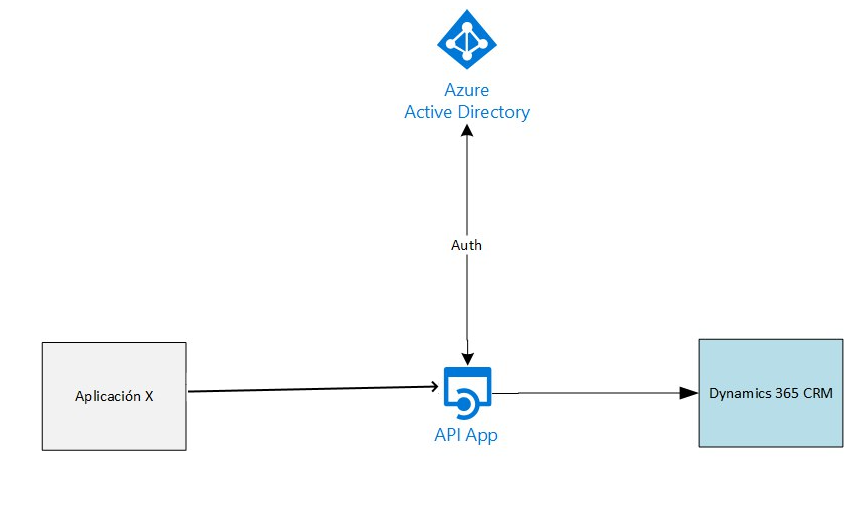
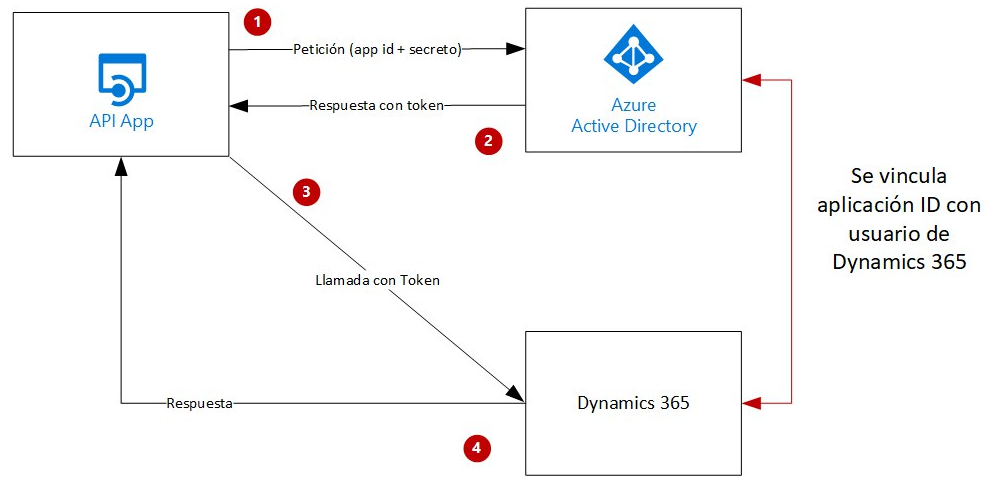
Nosotros controlamos tambien la securización de la API, podemos poner un sistema de api key, una lista blanca de IP o lo que necesitemos. El acceso de la API a D365 lo controlamos con Azure Active Directory y usuarios de aplicación.
– Velocidad de desarrollo: La gran cantidad de validaciones, accesos al CDS con queries complejas, que gracias al nuget de XRM para .Net, se desarrollan más rápido que, por ejemplo, con low code (siempre hablo de escenarios complejos).
– Calidad de desarrollo: Más velocidad y calidad en los desarrollos y peticiones de cambio. Tener un proyecto de código organizado, con sus capas y parametrizado, nos permiten encontrar rápidamente donde cambiar cuando es necesario. Cierto nivel de desacoplamiento de las capas nos permite cambiar cosas sin afectar al resto del proyecto. Los test unitarios y sobre todo, de integración con Dataverse nos permiten tener cierta seguridad ante un posible cambio, podemos tener cierta certeza de que no rompemos cosas que ya funcionan.
– Performance: Gracias que podemos cachear (los guardamos en memoria y no vamos a buscarlos todas las veces al CDS) ciertos datos, hemos conseguido un gran rendimiento en operaciones que a priori son muy costosas, como la gran cantidad de validaciones sobre datos maestros que teníamos que hacer. También nos permite ahorrar en llamas de API de CDS, que siempre penalizan.
– Control de la plataforma: Al desplegar nuestra API en Azure, tenemos el control total sobre la infraestructura donde corre la API. ¿existe alguna necesidad especial de securización? ¿es necesario escalar?
– Monitorización: Podemos tener un control absoluto sobre lo que pasa en nuestra API gracias a application insights sobre nuestro app service. ¿Cuánto tarda en responder la API?, ¿esta generando errores?, si es así, ¿Qué está pasando?
–Reutilización: Podemos usar la API para cualquier cosa que requiera tratar con D365 dentro del proyecto.
Si has llegado hasta aquí, gracias por leerte todo el tostón. Con esto solo pretendo, por un lado, poner en valor el trabajo realizado por los equipos técnicos, que se vea todo el trabajo que hay detrás y que hay detrás de una decisión técnica y por otro, intentar empatizar con los equipos que no son técnicos explicando el porqué de algunas decisiones que tomamos, que a priori pueden parecer “peores” en coste de desarrollo y/o tiempos, pero que en el medio plazo del proyecto, suelen ser mejor opción. Querer ahorrar tiempo en la implantación al principio, suele provocar el efecto contrario.
Como arquitectos, siempre hemos de buscar la mejor opción posible, lo que implica que sea: la que menos costes genere, la más sencilla de realizar y mantener pero que siempre se ajuste a las especificaciones.
Deja una respuesta